

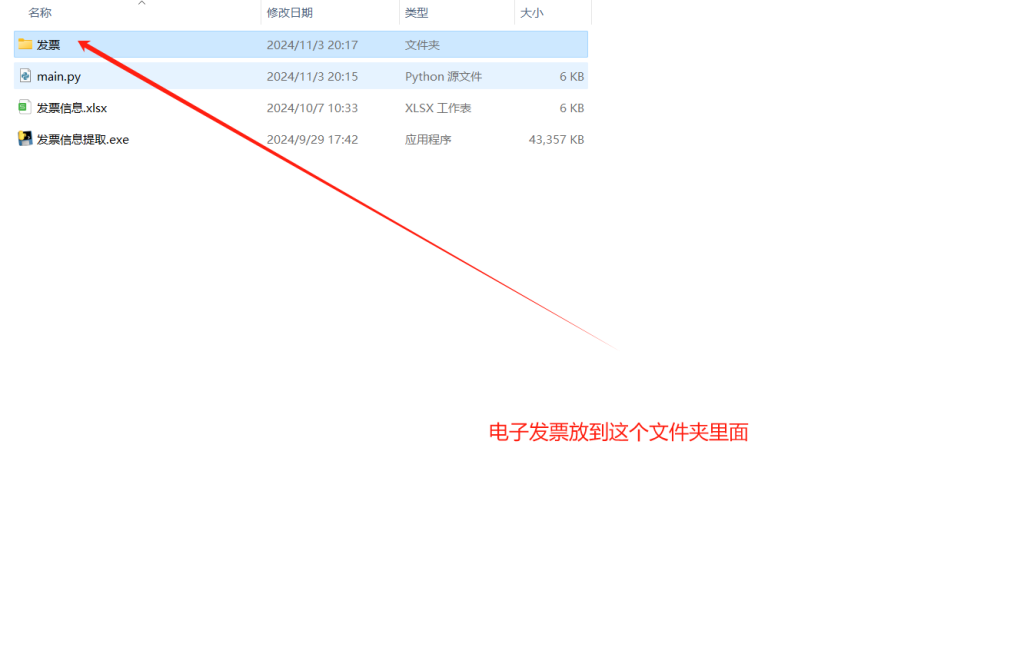
注意:需要把发票文件放到当前目录的《发票》文件夹里面如下图:
使用python来运行以下代码即可:
import pandas as pd
import numpy as np
import base64
import os
import re
import glob
import platform
import json
import logging
from tencentcloud.common import credential
from tencentcloud.common.profile.client_profile import ClientProfile
from tencentcloud.common.profile.http_profile import HttpProfile
from tencentcloud.common.exception.tencent_cloud_sdk_exception import TencentCloudSDKException
from tencentcloud.ocr.v20181119 import ocr_client, models
# 配置日志记录
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# 判断操作系统 Mac 还是 Win,并设置路径分隔符
if platform.system() == 'Windows':
chr = "\\"
elif platform.system() == 'Darwin':
chr = '/'
else:
chr = '/'
# 腾讯云API密钥(需要自行申请)
# 腾讯云OCR介绍https://cloud.tencent.com/document/api/866/36210
SecretId = '你的腾讯云API密钥'
SecretKey = '你的腾讯云API密钥'
# 设置发票文件夹路径为当前目录下的“发票”文件夹
base_folder = os.path.join(os.getcwd(), '发票')
# 检查文件夹是否存在
if not os.path.exists(base_folder):
logging.error(f"The folder '{base_folder}' does not exist.")
raise FileNotFoundError(f"The folder '{base_folder}' does not exist.")
# 获取发票文件列表
list_invoice_file = glob.glob(os.path.join(base_folder, '*.pdf'))
if not list_invoice_file:
logging.error(f"No PDF files found in '{base_folder}'.")
raise FileNotFoundError(f"No PDF files found in '{base_folder}'.")
# 定义处理发票的函数
def detail_invoice(path_file, n):
logging.info(f"Processing file {path_file}")
# 读取PDF文件并进行Base64编码
with open(path_file, "rb") as pdf_file:
encoded_string = base64.b64encode(pdf_file.read())
base64string = str(encoded_string, 'utf-8')
# 存储发票信息的字典
dirc = {}
try:
# 设置腾讯云API的凭证
cred = credential.Credential(SecretId, SecretKey)
httpProfile = HttpProfile()
httpProfile.endpoint = "ocr.tencentcloudapi.com"
clientProfile = ClientProfile()
clientProfile.httpProfile = httpProfile
client = ocr_client.OcrClient(cred, "ap-beijing", clientProfile)
# 设置请求参数
req = models.VatInvoiceOCRRequest()
params = {
"ImageBase64": base64string,
"IsPdf": True,
"PdfPageNumber": 1
}
req.from_json_string(json.dumps(params))
logging.info("Sending request to Tencent Cloud OCR API")
resp = client.VatInvoiceOCR(req)
logging.info("Received response from Tencent Cloud OCR API")
# 解析响应数据
reinfo = json.loads(resp.to_json_string())
# 处理发票信息
for i in reinfo["VatInvoiceInfos"]:
count = 0
name = i['Name']
nameraw = i['Name']
value = i['Value']
if str(name) in dirc:
while str(name) in dirc:
count += 1
name = nameraw + str(count)
dirc[name] = value
else:
dirc[name] = value
# 提取税率信息
tax_rate = None
for item in reinfo.get("Items", []):
tax_rate = item.get("TaxRate", None)
if tax_rate:
break
if tax_rate:
dirc['税率'] = tax_rate
# 将字典转换为DataFrame并添加到列表
df_detail = pd.DataFrame.from_dict(dirc, orient='index')
road.append(df_detail)
# 检查并处理关键信息
invoice_date = dirc.get('开票日期', '未知日期')
seller_name = dirc.get('销售方名称', '未知销售方')
amount_lowercase = dirc.get('价税合计(小写)', '未知金额')
invoice_number = dirc.get('发票号码', f'未知号码_{n}')
# 重命名文件
ReFileName = f"{invoice_date}_{seller_name}_{amount_lowercase}_{invoice_number}__{n}.pdf"
os.rename(path_file, os.path.join(base_folder, ReFileName))
logging.info(f"Renamed file to {ReFileName}")
except TencentCloudSDKException as err:
logging.error(f"Error processing file {path_file}: {err}")
print(err)
# 准备处理发票
road = []
n = 0
logging.info(f"Starting to process {len(list_invoice_file)} files")
for i in range(len(list_invoice_file)):
path_file = list_invoice_file[i]
n += 1
detail_invoice(path_file, n)
# 信息合并
logging.info("Combining processed information into final DataFrame")
df_detail_sheet = pd.concat(road, ignore_index=True, axis=1)
# 表格微调
df1 = df_detail_sheet.T
df1['re金额'] = df1['价税合计(小写)'].apply(lambda x: float(re.search("\d+(\.\d+)?", x).group()) if pd.notnull(x) else 0)
# 数据导出
output_file = '发票信息.xlsx'
logging.info(f"Exporting data to {output_file}")
df1.to_excel(output_file, index=False)
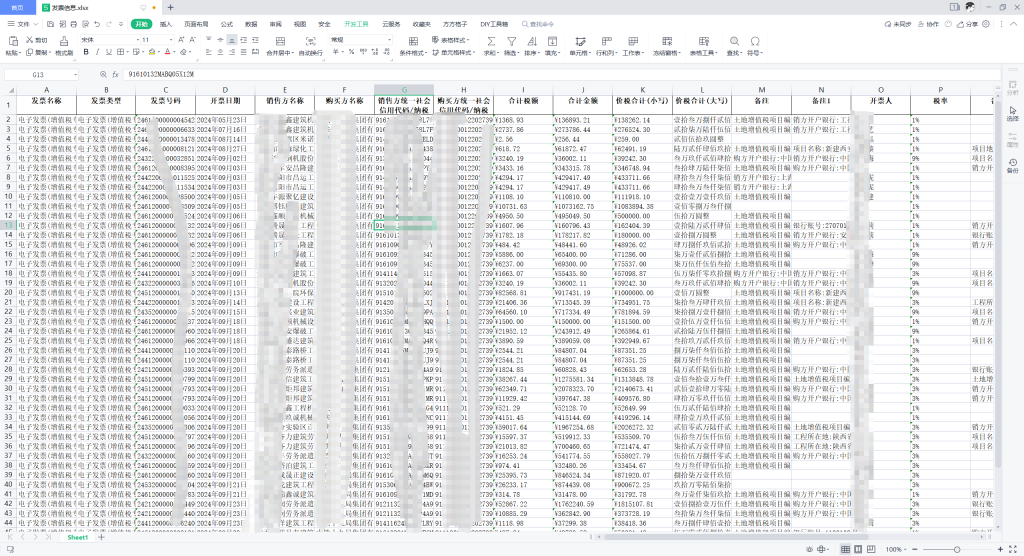
logging.info("Processing complete")运行后效果如下:
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END


暂无评论内容