

使用python批量提取发票信息减少工作量,
此方法是使用OCR识别,准确性不如腾讯云的付费版,如有高精度需求的请使用腾讯云付费版
目前仅支持以下模板的发票类型,如要适配其他类型的发票请自行修改。

import os
import PyPDF2
import pandas as pd
import re
def extract_invoice_info(pdf_path):
# 打开PDF文件
with open(pdf_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
page = reader.pages[0]
text = page.extract_text()
# 打印原始PDF内容
# print(f"原始PDF内容: {text}")
# 将文本按行分割
lines = text.split('\n')
# 提取第17到25行的内容
relevant_lines = lines[16:25]
relevant_text = ' '.join(relevant_lines)
# 打印提取的特定行内容
print(f"提取的特定行内容: {relevant_text}")
# 初始化发票信息字典
invoice_info = {
'发票号码': None,
'开票日期': None,
'销售方纳税人识别号': None,
'销方单位名称': None,
'不含税金额': None,
'税额': None,
'含税金额': None,
'税率': None,
'备注': None
}
# 提取发票号码
match = re.search(r"开票人:(?:建筑服务)?[::]?\s*(\d+)", relevant_text)
if match:
invoice_info['发票号码'] = match.group(1)
if '建筑服务' in relevant_text:
invoice_info['备注'] = '包含建筑服务'
# 提取开票日期
match = re.search(r"(\d{4}年\d{2}月\d{2}日)", relevant_text)
if match:
invoice_info['开票日期'] = match.group(1)
# 提取销售方纳税人识别号
match = re.search(r"(\d{15}[A-Z0-9]+)", relevant_text)
if match:
invoice_info['销售方纳税人识别号'] = match.group(1)
# 提取销方单位名称
match = re.search(r"(\d{15}[A-Z0-9]+)\s*([\u4e00-\u9fa5a-zA-Z0-9]+)", relevant_text)
if match:
invoice_info['销售方纳税人识别号'] = match.group(1)
invoice_info['销方单位名称'] = match.group(2)
# 提取不含税金额和税额
match = re.findall(r"¥([\d\.]+)", relevant_text)
if match and len(match) >= 2:
invoice_info['不含税金额'] = match[0]
invoice_info['税额'] = match[1]
# 提取含税金额
match = re.search(r"([\u4e00-\u9fa5]+圆[\u4e00-\u9fa5]*)\s*¥([\d\.]+)", relevant_text)
if match:
invoice_info['含税金额'] = match.group(2)
# 提取税率
match = re.search(r"(\d+%)", relevant_text)
if match:
invoice_info['税率'] = match.group(1)
return invoice_info
def process_pdf_files(pdf_folder, output_excel):
# 获取PDF文件夹中的所有PDF文件
pdf_files = [f for f in os.listdir(pdf_folder) if f.endswith('.pdf')]
# 初始化一个空的 DataFrame
df = pd.DataFrame(columns=[
'发票号码', '开票日期', '销售方纳税人识别号', '销方单位名称', '不含税金额', '税额', '含税金额', '税率', '备注'
])
# 遍历每个PDF文件并提取信息
for pdf_file in pdf_files:
pdf_path = os.path.join(pdf_folder, pdf_file)
try:
invoice_info = extract_invoice_info(pdf_path)
print(f"提取的发票信息: {invoice_info}") # 打印提取的信息
df = pd.concat([df, pd.DataFrame([invoice_info])], ignore_index=True)
except Exception as e:
print(f"处理文件 {pdf_file} 时出错: {e}")
# 将 DataFrame 保存到 Excel 文件
df.to_excel(output_excel, index=False)
# 使用示例
pdf_folder = 'PDF'
output_excel = '发票信息汇总.xlsx'
process_pdf_files(pdf_folder, output_excel)
print(f"发票信息已保存到 {output_excel}")
使用后效果如图所示:
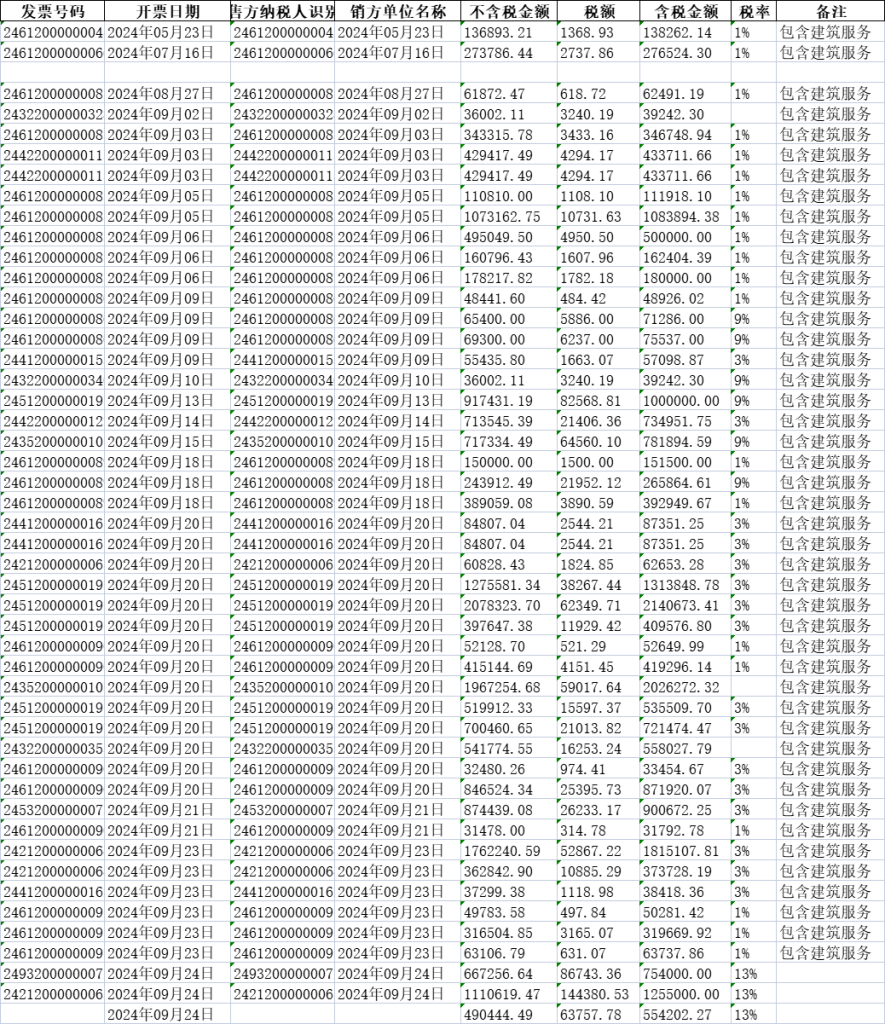
通过百度网盘分享的文件:发票信息提取.rar
链接:https://pan.baidu.com/s/1_p6Sb3I6Gad2iMk0t_jDHg?pwd=5f8z
提取码:5f8z
–来自百度网盘超级会员V3的分享
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END


暂无评论内容